生产者-消费者模式指的是:生产者和消费者在同一个时间段共用同一段空间,在这段时间内,生产者负责往存储空间生产数据,而消费者则负责消费数据。实际上存在很多类似的场景:消息中间件就可以看做这种模式的应用,客户端请求负责把请求消息发送给消息中间件,然后由服务器负责从消息中间件获取请求并进行响应;还有网络编程中Socket也可以看做是生产者消费者模式的应用,etc。
为了简化问题的研究,现在仅仅考虑一种简单的场景:生产者负责生产“authorA–>titleA”和“authorB–>titleB”两种数据(这两种数据是一种代表author和title可以认为是生产的两种组件,并无实际意义),消费者则负责从中取数据。根据前面对线程安全的研究,该场景可能会出现取到的数据不完整或者重复取数据的情况。出现数据完整表现在:生产者生产完author后,还没有来得及生产title便被消费者取走了,这种情况需要使用线程同步机制实现;取到重复的数据表现在:消费者取到完整的数据后,没有及时通知生产者继续生产,导致第二次取到的数据仍然是上次取到的数据,显然这种情况需要使用等待/通知机制实现。
首先我们来定义需要生产的组件:Content。Content包括了两个组件信息:author和title,并提供了消费者和生产者执行的get和set方法
package com.ddkk.concurrency;
import java.util.concurrent.TimeUnit;
/**
* DDKK.COM 弟弟快看,程序员编程资料站 16-4-4.
*/
public class Content {
//标题
private String title;
//作者
private String author;
//是否开始生产的标志,默认开始生产
private boolean produce = true;
/**
* 消费者执行的方法
* @param author
* @param title
* @throws InterruptedException
*/
public synchronized void set(String author, String title) throws InterruptedException {
//如果没有开始生产就阻塞等待
while (!produce) {
super.wait();
}
//设置作者
this.setAuthor(author);
//休眠1秒
TimeUnit.SECONDS.sleep(1);
//设置标题
this.setTitle(title);
System.out.println("[生产者]:" + this.getAuthor() + " --> " + this.getTitle());
//设置标志位为false。表示可以取数据了
produce = false;
//唤醒正在等待的线程
super.notify();
}
/**
* 消费者执行的方法
* @throws InterruptedException
*/
public synchronized void get() throws InterruptedException {
//如果已经开始生产了就阻塞等待
while (produce){
super.wait();
}
System.out.println("[消费者]:" + this.getAuthor() + " --> " + this.getTitle());
//让生产者继续生产
produce = true;
super.notify();
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
然后,我们定义了生产者,把生产者执行的生产任务放在一个线程中单独执行:
package com.ddkk.concurrency;
/**
* DDKK.COM 弟弟快看,程序员编程资料站 16-4-4.
*/
public class Producer implements Runnable {
private Content content;
public Producer(Content content) {
this.content = content;
}
public void run() {
boolean flag = true;
for (int i = 0; i < 6; i++){
if (flag){
try {
content.set("authorA","titleA");
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
}else {
try {
content.set("authorB","titleB");
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
}
}
接着,我们定义消费者,消费者的消费任务也放在线程中单独执行:
package com.ddkk.concurrency;
/**
* DDKK.COM 弟弟快看,程序员编程资料站 16-4-4.
*/
public class Consumer implements Runnable {
private Content content;
public Consumer(Content content) {
this.content = content;
}
public void run() {
for (int i = 0; i < 6; i++){
try {
content.get();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
最后,就是我们的测试代码了:
package com.ddkk.concurrency;
/**
* DDKK.COM 弟弟快看,程序员编程资料站 16-4-4.
*/
public class ProducerConsumerModeTest {
public static void main(String[] args){
Content content = new Content();
Thread producer = new Thread(new Producer(content),"Producer");
Thread consumer = new Thread(new Consumer(content),"Consumer");
producer.start();
consumer.start();
}
}
运行上面的测试代码,得到的结果如下:
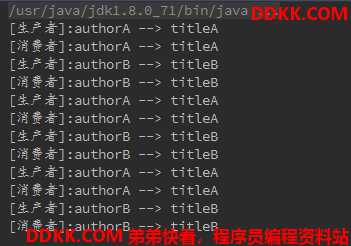
从运行结果可以看出,只有当生产者生产了数据后消费者才会从中取数据,这样取到的数据就不会重复。由一点要注意的是:消费者线程循环的次数必须和生产者线程一致,不然就会出现消费者一直等待生产者生产数据的情况,这点从代码中就可以看出,因为如果生产者没有继续生产的话消费者调用wait方法便会阻塞等待直到有数据。